













【AI專知】強化學習是什麼?原理、類型、實際應用全解析

從擊敗人類棋王的 AlphaGo,到讓 ChatGPT 學會說人話的 RLHF,強化學習(Reinforcement Learning,RL) 是近十年 AI 最關鍵的突破技術之一。
不過,在 AI 時代,你知道強化學習是什麼嗎?本文將帶你從原理到應用,一次搞懂它,讓你在未來站穩腳步。
想要擁有一台心儀的手機記得到傑昇通信,挑戰手機市場最低價再享會員尊榮好康及好禮抽獎券,舊機也能高價現金回收,門號續約還有高額優惠!快來看看手機超低價格!買手機.來傑昇.好節省!
什麼是強化學習?
強化學習是機器學習三大核心分支之一,與「監督式學習」和「非監督式學習」並列。
核心概念是:一個智能體(Agent)在環境中不斷嘗試,透過獎勵與懲罰回饋,學習出能最大化長期累積報酬的行動策略。
最直觀的比喻是訓練狗狗:做對了給零食(正獎勵),做錯了不給(負獎勵)。幾百次嘗試後,狗自然學會了。強化學習的邏輯相似,只是把「狗」換成演算法。
與監督式學習的最大差異在於:監督式學習需要人工標記大量正確答案,而 RL 不需要標記資料,訓練資料來自智能體與環境的直接互動。
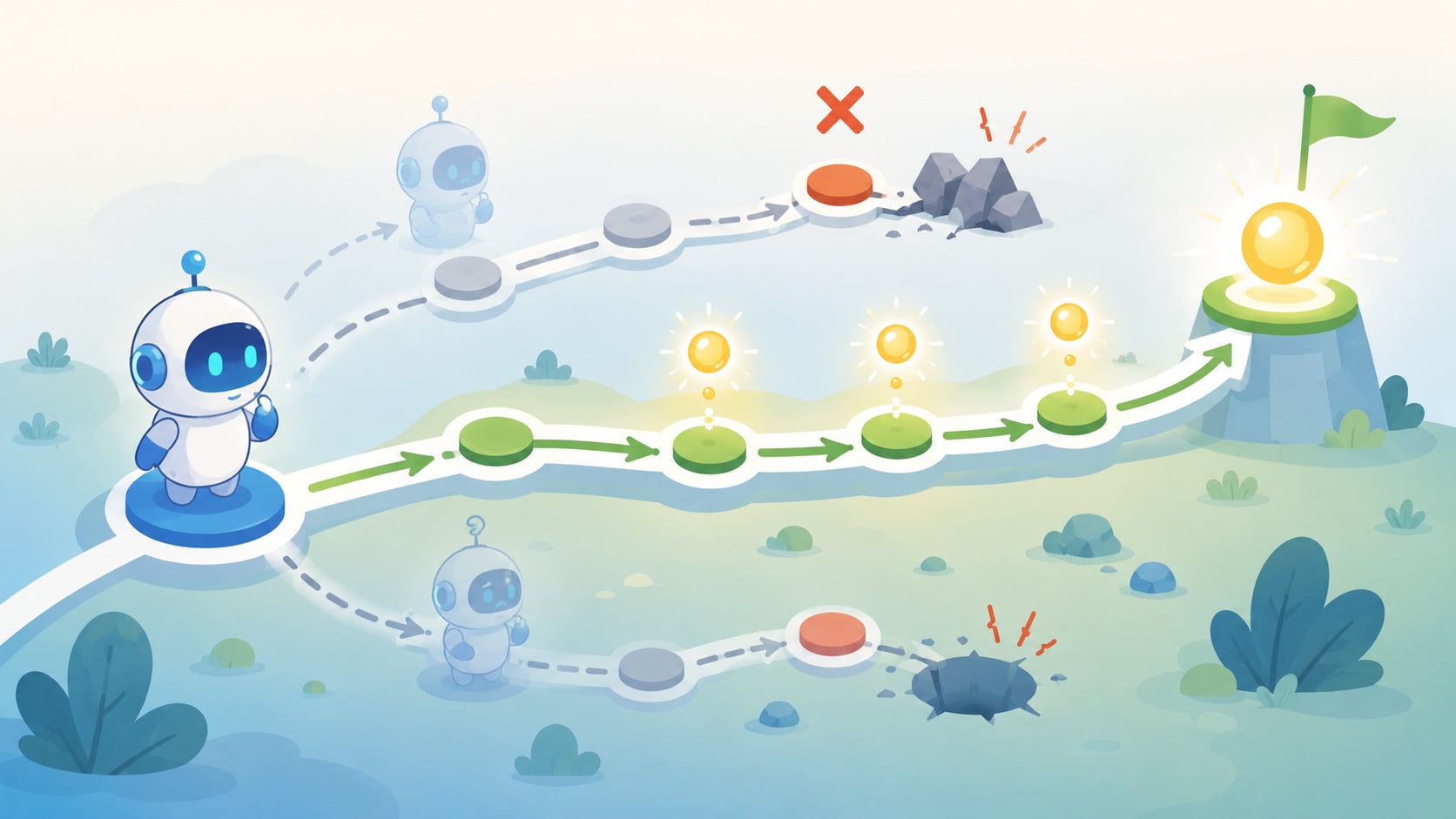
五大核心組成元素
-
智能體(Agent):學習與決策的主體
-
環境(Environment):智能體所處的世界,回傳新狀態與獎勵
-
狀態(State):當前環境的快照,幫助智能體決策
-
獎勵(Reward):對動作好壞的即時數值評分
-
策略(Policy):從狀態到動作的映射,以符號 π 表示
另有價值函數(Value Function) 負責預測未來累積獎勵,讓智能體具備「犧牲眼前小獎勵、換取長期大收益」的能力。
三類主流演算法
價值導向(Value-Based)
估計每個狀態或動作的長期價值,再貪婪選擇最高值動作。
-
Q-Learning:透過 Bellman 方程式遞迴更新 Q 值,最經典的 RL 演算法
-
DQN(Deep Q-Network):結合深度神經網路,讓 RL 直接從像素輸入學習,首次讓 AI 超越人類玩 Atari 遊戲
策略導向(Policy-Based)
直接對策略參數化並優化,適合連續動作空間(如機器人關節控制)。
-
PPO(Proximal Policy Optimization):透過限制每次更新幅度確保訓練穩定,目前是 RLHF 訓練 LLM 的事實標準演算法
Actor-Critic
結合上述兩者優點:Actor 更新策略,Critic 評估動作價值並指導 Actor。代表演算法有 A3C、SAC、TD3,是目前最主流的 RL 架構。

RLHF:讓 ChatGPT 學習說人話
以人類回饋進行強化學習(RLHF) 是生成式 AI 崛起的幕後功臣,完整流程分三步:
-
有監督微調(SFT):用人類示範資料讓模型初步學會有用回應的格式
-
訓練獎勵模型:讓人類標記者對多個回應排名,訓練出能預測人類偏好的獎勵模型
-
PPO 優化:以獎勵模型作為回饋訊號,用 PPO 持續更新語言模型策略
ChatGPT、Claude、Gemini 均採用此流程。近年更延伸出 RLAIF(用 AI 取代人類標記)與 DPO(Direct Preference Optimization,繞過獨立獎勵模型、更簡潔穩定)兩大變體。
強化學習:跨產業實際應用
| 產業 | 應用場景 |
| 金融 | 演算法交易、投資組合動態調整、風險對沖 |
| 汽車 | 自駕車路徑規劃、交通號誌優化 |
| 機器人 | 靈巧操作、步態學習、倉儲路由 |
| 科技 | Google 以 RL 降低資料中心冷卻能耗約 40% |
| 半導體 | DeepMind 以 RL 輔助晶片布局,超越資深工程師水準 |
| 生成式 AI | RLHF 對齊 LLM,使回應更有幫助、安全且誠實 |
強化學習的優勢與挑戰
主要優勢:無需標記資料、能處理延遲回饋、持續自我改善、適應動態環境。
核心挑戰:
-
樣本效率低:需要大量環境互動才能收斂
-
獎勵黑客(Reward Hacking):智能體可能鑽獎勵函數漏洞,達到高分但違背設計意圖
-
可解釋性不足:深度 RL 決策過程是黑箱,在金融與醫療等需要合規的領域構成障礙
結語:AI 發展的重要因素
強化學習的本質是賦予機器在不確定環境中自主追求目標的能力。
從你每天滑動的推薦演算法,到與你對話的 AI,再到城市中測試的自駕車,RL 早已悄悄融入日常。理解它,是讀懂未來十年 AI 進展最重要的一把鑰匙。
常見問題(FAQ)
Q1:強化學習是監督式學習嗎?
不是。監督式學習需要人工標記好的資料,強化學習不需要,它靠「試錯+獎懲」自己學習。
Q2:ChatGPT 有用到強化學習嗎?
有。ChatGPT 使用 RLHF(以人類回饋進行強化學習),讓模型學會給出更有幫助、更安全的回答。
延伸閱讀:【AI專知】神經網路(Neural Networks)是什麼?原理、優缺點、實際應用總整理
延伸閱讀:【AI專知】ASIC 是什麼?優勢在哪?從 AI 算力到智慧裝置的核心
延伸閱讀:【AI專知】過度擬合(Overfitting)是什麼?原因、辨識、防止方法一次搞懂!
手機哪裡買價格最便宜划算有保障?
買手機當然要選值得信賴的傑昇通信。
身為全台規模最大、擁有40年專業經營的通訊連鎖,傑昇始終堅持「挑戰手機市場最低價」,再加上會員專屬好康、好禮抽獎券,讓您買得划算又有驚喜!舊機還能高價現金回收,門號續約更享高額優惠,全台超過150間門市隨時為您服務,一間購買連鎖服務,一次購買終生服務,不只買得安心,更能用得開心。買手機.來傑昇.好節省!




























